Hvordan vi anvender teknikker bygget på maskinlæring og dyp læring for å utvikle bedre, mer pålitelige transaksjonsovervåkingssystemer.
Morgendagens transaksjonsovervåking
To av de mest omtalte og diskuterte temaene de siste årene knyttet til finanssektoren har vært kunstig intelligens og anti-hvitvasking. Mens førstnevnte har blitt et symbol på modernisering og effektivisering, så har sistnevnte blitt den bekmørke skyen som har gitt oss et innblikk i akkurat hvor lite moderne og effektive visse prosesser kan være.
Artikkelen starter med å gjennomgå dagens situasjon for anti-hvitvasking, hvor dagens systemer, lovkrav og anbefalinger fra tilsynsmyndigheter vil bli drøftet. Deretter diskuteres det om logikken, metodikken og tilpasningsevnen til dagens regelbaserte systemer er tilstrekkelig til å levere på kravene til et moderne transaksjonsovervåkingssystem. Videre ser vi på hvordan vi kan utvikle overvåkingssystemer ved bruk av veiledet og uveiledet maskinlæring, og hvordan systemer som følger metodikken foreslått i denne artikkelen har vist seg å levere opptil flere ganger mer presise resultater sammenlignet med sine forgjengere og konkurrenter. Konseptene og fremgangsmåten foreslått i denne artikkelen er altså ikke konseptuelle, men basert på systemer som per i dag er i produksjon for noen av Nordens og Europas ledene finansforetak.
Hva er dagens sitasjon?
15. oktober 2018 ble EUs 4. hvitvaskingsdirektiv implementert i Norge gjennom ny hvitvaskingslov. Regelverket strammer inn kravene knyttet til avdekking og forebygging av hvitvasking og terrorfinansiering hos finansinstitusjoner. Institusjonens kundetiltak for å sikre forståelse av kundens eier og reelle rettighetshavere er sentralt. En viktig presisering er knyttet til kravet om virksomhetsinnrettet risikovurdering, og at institusjonens rutiner, prosesser og systemer er tilpasset risikoeksponeringen. For banker og kredittinstitusjoner betyr dette blant annet krav om elektroniske overvåkingssystemer. Finanstilsynet kan også pålegge andre institusjoner å implementere tilsvarende systemer, avhengig av mengden transaksjoner det er snakk om. I EUs 6. hvitvaskingsdirektiv foreslås det også i større grad å kriminalisere transaksjoner som kun er indirekte knyttet til finansiell kriminalitet. Dette vil stille ytterligere krav til institusjonens transaksjonsovervåking.
Elektronisk transaksjonsovervåking hos norske finansforetak fungerer i stor grad i dag ved at automatiserte, regelbaserte systemer identifiserer mistenkelig adferd. Reglene er som oftest relativt selvforklarende, og følger formen «hvis X, så Y». Vanligvis er reglene definert av eksperter med dyp kjennskap til svindel, hvitvasking og terrorfinansiering. Et enkelt eksempel på en slik regel er: «Sjekk alle transaksjoner som kommer fra land X». Systemet flagger så alle disse transaksjonene som mulig svindel, og det er opp til anti-hvitvaskingsansvarlig å ta en vurdering på om dette er en hendelse som er mistenkelig nok til å sendes videre til Økokrim.
Det har oppstått en del problemer de siste årene med overvåkingsrutiner som følger denne formen. Hovedutfordringene kan deles opp i to kategorier:
1) økende mengder falske positive og
2) økende mengder falske negative.
Falske positive er transaksjoner som det automatiserte systemet vurderer som mistenkelige, men som i virkeligheten ikke er det. Dette fører til mye manuelt arbeid for finansforetak fordi menneskelige ressurser må brukes for å vurdere slike tilfeller hver for seg. Det er ikke uvanlig at et stort europeisk finansforetak har 3-5 fulltidsresurser for dette arbeidet alene. For å eksemplifisere kan vi gå tilbake til den geografiske regelen om å kontrollere alle transaksjoner fra land X. Sannsynligvis vil de fleste slike transaksjoner handle om helt normale situasjoner, som at utvandrende besteforeldre i land X sender bursdagsgaver hjem.
Generelt kan man si at falske positive kommer av at de regelbaserte systemene ikke er spesifikke nok til å skille mellom hva som er mistenkelig og hva som ikke er mistenkelig. I tillegg ser vi at systemer ofte selges som relativt standardiserte løsninger med begrensede tilpasningsmuligheter. Med begrensede muligheter menes det at logikken i reglene ofte er predefinert av systemleverandøren, slik at institusjonen bare har mulighet til å justere sensitiviteten i reglene. For eksempel kan man selv bestemme om man ønsker at alle transaksjoner over NOK 50 000 eller NOK 100 000 skal bli flagget i et gitt tilfelle. Dette fører ofte til irrelevante og lite selskapsspesifikke regler, som igjen fører til upresise systemer.
Derimot er det helt andre konsekvenser av dårlige transaksjonsovervåkingssystemer som er mest synlige utad, og disse knytter seg til falske negative. Falske negative er det vi i økende grad har lest om i nyhetene de siste årene: mistenkelige transaksjoner som ikke fanges opp av systemene.
Årsaken til dette er at dagens svindlere og hvitvaskere viser seg mer utspekulerte enn «regelsettene» som brukes i dagens automatiserte løsninger.
De kriminelle miljøene overvåker finansinstitusjonenes transaksjonsovervåkingssystemer, og tilpasser seg disse etter hvert som reglene endres. For å konkludere så finner vi i dag alt for mye, bare ikke det vi leter etter.
Som følge av denne problematikken er det ikke bare krav om å ha automatiserte overvåkingssystemer tilsynsmyndighetene fokuserer på i hvitvaskingsloven. Vel så viktig er det at de automatiserte systemene som tas i bruk er tilpasset den virksomheten institusjonen utøver. Finanstilsynet er klare på at systemene skal være egnet til å avdekke hvitvaskings- og terrorfinansieringsrisikoer som er identifisert i den rapporteringspliktiges risikovurdering. Utfordringen ligger dermed i å tilpasse systemer til den bestemte virksomheten, noe vi i denne artikkelen argumenterer for at er svært vanskelig å få til så lenge det er regelbasert metodikk som anvendes, og desto vanskeligere så lenge leverandørene utvikler hyllevaresystemer.
Hva er kunstig intelligens, og hva er maskinlæring?
Enkelt forklart er kunstig intelligens hva enn som kan få en maskin til å gjøre prediksjoner. Som illustrert i figur 1 er både regelbaserte systemer, maskinlæring og dyp læring alle eksempler på kunstig intelligens. Derimot er visse former for kunstig intelligens mer intelligente enn andre. Vi argumenterer for å rette fokus fra regelbaserte systemer til systemer som anvender maskinlæringsteknikker.
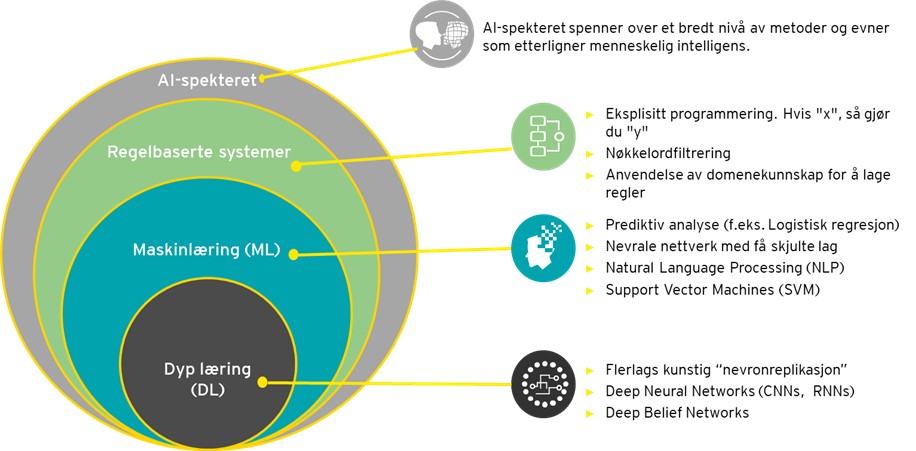
Maskinlæring er et sett analytiske metoder basert på algoritmer med mål om å finne verdifulle sammenhenger i store mengder data. Den store fordelen maskinlæringsalgoritmer har over regelbaserte systemer, er at mens sistnevnte begrenser seg til å se etter akkurat det den har fått beskjed om, så prøver førstnevnte å finne verdifulle sammenhenger i det tilgjengelige datagrunnlaget, uten å eksplisitt bli fortalt hvor den skal se. Dette fører til at vi nå har muligheten til å identifisere mistenkelig adferd som vi før i det hele tatt visste at var mistenkelig.
I tillegg vil maskinlæringsalgoritmer kunne dekke et mye bredere datagrunnlag enn hva vi ser de regelbaserte systemene ta for seg i dag. Mens de regelbaserte systemene sjeldent kan håndtere mer enn 10-12 input-variabler, bruker de maskinlæringsmodeller vi har utviklet til transaksjonsovervåking ofte om lag 100 forskjellige input-variabler. Anvendt riktig fører dette til et langt mer helhetlig bilde av kunder, kontoer og transaksjoner når det vurderes om en handling er mistenkelig eller ikke.
Vi kan dermed si at hvis regelbaserte systemer er fundamentet i transaksjonsovervåking, så er maskinlæring fundamentet i adferdsovervåking.
Muligheten for anvendelse av et bredere og dermed mer selskapsspesifikt datagrunnlag betyr også at vi har mulighet til å utvikle systemer som er totaltilpasset det spesifikke selskapet. I tillegg vil dette åpne opp for flere muligheter i arbeidet med å fange opp transaksjoner som bare indirekte knytter seg til kriminell aktivitet, et fokusområde i EUs 6. hvitvaskingsdirektiv.
Hvordan brukes maskinlæring til transaksjonsovervåking?
For å forklare hvordan vi kan utvikle systemer basert på maskinlæring er det nødvendig å skille mellom det vi kaller veiledet maskinlæring og det vi kaller uveiledet maskinlæring (supervised vs. unsupervised learning). Veiledet maskinlæring er det vi bruker når vi allerede har et sett eksempler på hva som er riktig svar i en vurdering, og vil bygge en algoritme som kan fortsette å finne samme type svar for oss i fremtiden. Uveiledet maskinlæring er modeller som ikke blir veiledet til hva den skal se etter, men som heller har som mål å finne naturlige strukturer i dataen. Et grunnleggende krav til et automatisert transaksjonssystem er at det skal kunne prosessere transaksjonsbevegelser og melde fra om potensielle mistenkeligheter. Slik adferd vil deretter bli vurdert av eksperter på området, før det potensielt blir sendt en Mistenkelig Transaksjon (MT) melding videre til Økokrim. Dette betyr at vi er nødt til å ha et system som har fått en instruks om hva det skal lete etter – nemlig potensielle MT-saker. Et effektivt transaksjonsovervåkingssystem må dermed bygge på veiledet læring.
Når vi bruker regelsystemer er det problematisk at modellene våre bare finner mistenkelige transaksjoner som vi selv har definert. Når vi bruker veiledet maskinlæring har vi et lignende problem: Siden algoritmen bare lærer seg å finne samme type svar som vi kan vise til historisk, så vil den bare finne samme type saker som vi allerede gjorde med regelsystemet. Så, hvis vi bare fant en tiendedel av de reellt mistenkelige tilfellene med regelsystemet vårt, betyr det at algoritmen finner de samme sakene i fremtiden – Men reelt sett har vi ikke løst problemet med falske negative.
Hvordan finne noe man ikke vet hvordan ser ut?
Selv om dette spørsmålet byr på utfordringer uansett hvilke teknikker overvåkingssystemet er bygget på, så har maskinlæringssystemer noen fordeler som gjør problemet mer håndterlig. Dette er fordi regelbaserte systemer må utvikles blindt basert på kvalitative meninger om hva som er mistenkelig og hva som ikke er, uten å ha noen innebygget kvantitativ metode for å støtte disse meningene. Her brukes det ofte kunnskap om hva som har vært mistenkelig tidligere, eller hva som har blitt evaluert som mistenkelig hos andre finansforetak i andre land. Dette fører til:
1) at regelbaserte systemer aldri vil kunne være noe mer enn reaktive systemer som prøver å fange opp allerede kjente, tidligere påviste hvitvaskingsmetodikker og
2) at slike regler kan ha basis i kundebaser som er svært forskjellige fra ens egen, som betyr at systemene i liten grad kan skreddersys til det bestemte finansforetaket.
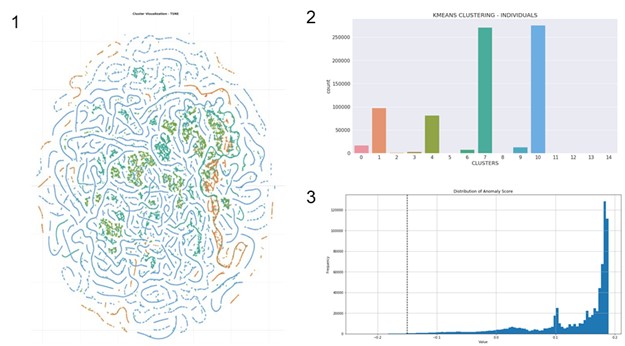
Veiledet maskinlæring står overfor mange av de samme problemene. Derimot vet vi nå at uveiledet metodikk kan anvendes for å forske seg frem til interessante adferdsmønstre i datagrunnlag selv om vi ikke vet nøyaktig hva vi leter etter. Vi har også lært at selv om uveiledet metodikk ikke kan brukes direkte til å finne mistenkelig adferd, så kan det brukes til å finne avvikende adferd. Dette gjøres ved å fange opp små og store grupperinger med lignende adferd, samt smarte vurderinger av all adferd etter hvor lik «normalen» den er. Slike algoritmer blir derfor anvendt på store historiske datasett for å lære nye sammenhenger og karakteristikker i datagrunnlaget utover den begrensede karakteristikken vi får fra institusjonens historiske MT-meldinger. Illustrasjon 1 og 2 i figur 2 viser eksempler på output fra ulike algoritmer som har fått i oppgave å gruppere transaksjoner. Her ser vi at det er stor forskjell mellom antallet transaksjoner i hver av gruppene, og det er gjerne de mindre gruppene vi velger å undersøke videre.
Illustrasjon 3 i figur 2 viser en algoritme som har fått i oppgave å rangere hver transaksjon etter hvor «normal» den er. Linjen til venstre illustrasjonen er det definerte cut-off punktet for når en transaksjon vurderes som for langt fra normalen.
Videre kommer den utfordrende jobben med å vurdere om unormal adferd er det samme som mistenkelig adferd. Her brukes AML-eksperter til å kvalitativt vurdere om dette er adferd som burde vært undersøkt videre og eventuelt rapportert inn til Økokrim. Hvis adferden vurderes som mistenkelig tagges transaksjonene i systemet. Det er funnene fra de uveiledede algoritmene, etter nøye screening fra AML-eksperter, som videre skal brukes til å veilede det endelige transaksjonsovervåkingssystemet, i tillegg til finansinstitusjonens historiske MT-meldinger. Forskjellen på slik bruk av AML-eksperter sammenlignet med hvordan de brukes for regelutvikling er at ekspertene ikke lenger definerer hvordan vi finner mistenkelig adferd, bare kvalitetssjekker at det faktisk er mistenkelig adferd. Dette bidrar til bedre og mer effektiv utnyttelse av fagekspertene.
Etter å ha tagget et representativt antall saker av mistenkelig adferd er vi klare for å trene et sett med veiledede modeller til å finne lignende adferdsmønstre i nye data. Her er det viktig å notere seg at de veiledede modellene vi nå er klare for å anvende ikke lenger trenger å basere seg på tidligere MT-meldinger alene, og vi vil derfor ikke være begrenset til å utelukkende finne nye saker som ligner på tidligere MT-saker. Funnene som de veiledede algoritmene kommer tilbake med vil igjen bli levert til analyse av ekspertgruppen. Hvis de viser seg mistenkelige, vil også disse bli tagget inn i systemet. Denne iterative læringsfasen fortsetter inntil vi ser oss fornøyde med den gruppen mistenkelige adferd vi nå har fanget opp, og evaluert at dette er godt nok til å veilede det endelige transaksjonssystemet. Det er viktig å presisere at det alltid jobbes med ulike subsett av det historiske datagrunnlaget når ulike modeller trenes og testes. Dette er fordi det lar oss teste hvordan algoritmene fungerer i en produksjonssetting med nye transaksjoner.
Til slutt har man et sett med ferdigtrente algoritmer basert på ulike veiledede maskinlæringsteknikker. Hver enkelt algoritme blir så vurdert etter hvor nøyaktig den er, før alle algoritmer får en prioriteringsvekt i systemet. Prioriteringsvekten brukes til å evaluere hvor mye systemet skal høre på hver enkelt algoritme. Når transaksjonssystemet blir eksponert for nye transaksjoner, produserer systemet en liste over transaksjoner som over alle modellene sammenlagt scorer over en gitt sannsynlighetsgrad for mistenkelig adferd. Listen er risikobasert, og det manuelle arbeidet starter da med den potensielt mest risikable transaksjonen, i motsetning til tradisjonelle systemer der disse listene i større grad er tilfeldige. I tillegg til å levere en beregnet sannsynlighetsgrad for hver enkelt transaksjon, leverer systemet også en forklaringsmatrise over elementene som førte til at akkurat den bestemte transaksjonen ble fanget opp. Dette fører til ytterligere effektivisering av transaksjonsovervåkingsprosessen fordi man ikke lenger trenger å bruke tid på å identifisere hvorfor systemet fanget opp en bestemt transaksjon, men heller fokusere på om modellens logikk holder vann i det bestemte tilfellet.
Oppsummert
Innledningsvis ble begrepene falske positive (FP) og falske negative (FN) introdusert for å gruppere problemene vi ser i dagens transaksjonssystemer, nemlig mistenkelige transaksjoner som systemene vurderer som ikke-mistenkelige, og ikke-mistenkelige transaksjoner som systemene vurderer som mistenkelige. I tillegg til korrekt positive (KP) og korrekt negative (KN), som henholdsvis betyr hvor mange mistenkelige transaksjoner vi korrekt flagger og hvor mange ikke-mistenkelig transaksjoner vi korrekt ikke flagger, er dette variabler brukt for å regne Precision og Recall.
Dette er to av de viktigste måltallene som brukes for å vurdere om en maskinlæringsalgoritme presterer eller ikke.
Precision, definert som, KP/KP+FP, måler hvor mange av de flaggede transaksjonene en modell gjør som faktisk er mistenkelige, mens Recall, definert som KP/KP+FN, måler hvor mange av alle mistenkelige transaksjoner som blir flagget av modellen.
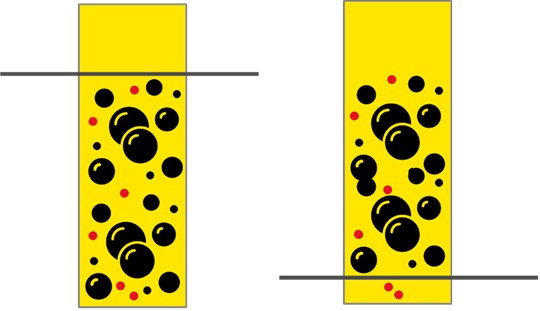
Hvis vi prøver å tenke gjennom hvordan vi ville gått frem for å score best mulig på enten Recall eller Precision, så kommer vi raskt frem til at begge deler egentlig er ganske lett. Ønsker vi å flagge alle mistenkelige transaksjoner, altså 100 % Recall, så flagger vi rett og slett alle transaksjoner. Dette trenger vi ikke engang en modell for å oppnå. Et slikt tilfelle er illustrert til venstre i figuren under, hvor de svarte prikkene representerer normale transaksjoner og de røde representerer mistenkelige transaksjoner. Denne strategien vil derimot føre til svært mye jobb for den eller de ansvarlig for å prosessere modellens funn. Hvis vi på andre siden ønsker å ha en utelukkende stor andel korrekt flaggede transaksjoner, altså høyest mulig Precision, så velger vi ekstreme verdier for seleksjon, slik at bare de mest åpenbare tilfellene av hvitvasking blir flagget. Dette er illustrert til høyre under. En slik strategi ville ført til at alt for mange hvitvaskingstilfeller slapp gjennom og forble uidentifisert.
Som tidligere nevnt er en effekt av regelbaserte systemer at de flagger for mange transaksjoner, som dermed fører til at AML-ansvarlig må gjøre for mange manuelle kontroller. På grunn av denne effekten, og irritasjonen som følger en slik mengde manuelt arbeid, så ser vi nå et skifte mot at systemer som melder fra om et mindre antall saker automatisk blir favorisert. Dette er et klart faresignal om at Precision blir for mye vektet kontra Recall.
Det er i kombinasjon at de to måltallene gir grunnlag for vurdering. Det vi optimalt ønsker er en god trade-off mellom Precision og Recall, eller som nevnt innledningsvis: maksimalt antall korrekt identifisert mistenkelig adferd, og samtidig minimalt antall feilaktig identifisert mistenkelig adferd.
Resultatene i Precision og Recall vi har oppnådd hos klienter i Norge, Norden og resten av Europa har gitt oss en god indikasjon på at metodikken foreslått i denne artikkelen produserer mer intelligente systemer sammenlignet med de regelbaserte hyllevaresystemene som oftest anvendes i dag. Normalt har vi sett en økning i begge måltallene fra ensifret til 20-30% sammenlignet med systemene anvendt hos klienten fra før. Dette vil si at systemer utviklet basert på diskutert metodikk ofte gir 4-5 ganger så relevante treff sammenlignet med de regelbaserte systemene som allerede er på plass hos institusjonene. Her er det viktig å igjen presisere at dette ikke måles i MT-saker funnet, men saker funnet som AML ansvarlig hos klienten vurderer som verdt nøyere gjennomgang. Arbeidet har dermed gjort oss betydelig mer optimistiske til at anvendelse av nye teknikker slik som maskinlæring og dyp læring kan hjelpe finansindustrien i kampen mot hvitvasking, svindel og terrorfinansiering. Ta gjerne kontakt med forfatterne av artikkelen hvis du ønsker mer informasjon om hvordan EY kan hjelpe din organisasjon med å bekjempe finansiell kriminalitet.